Kernel Matrix Multiplication Cuda
Execute the following cell to write our naive matrix multiplication kernel to a file name matmul_naivecu by pressing shiftenter. Each element in C.

Simple Matrix Multiplication In Cuda Youtube
Matrix Multiplication in CUDA by using TILES.
Kernel matrix multiplication cuda. Each thread block consists of 256 threads and each thread computes an 8 x 8 block of the 128 x 128 submatrix. Int y blockIdx. Computing y ax y in parallel using CUDA _global_void saxpy_parallelint n float alpha float x float y int i blockIdxxblockDimx threadIdxx.
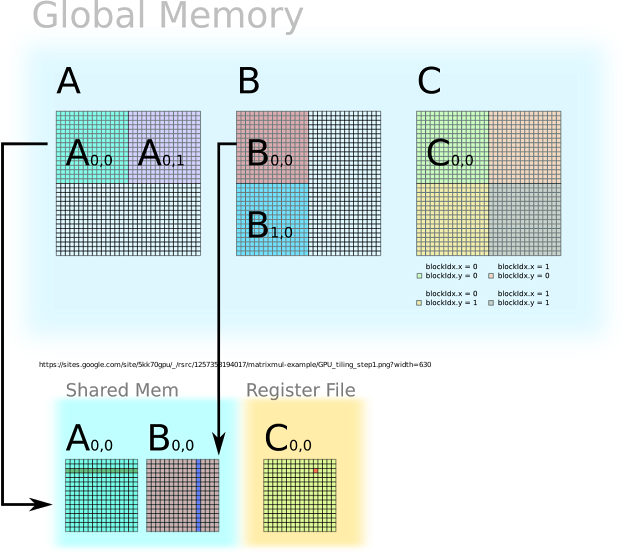
Obvious way to implement our parallel matrix multiplication in CUDA is to let each thread do a vector-vector multiplication ie. The above sequence is arranged in the increasing order of efficiency performance 1st being the slowest and 5th is the most efficient fastest. In the kernel because of the shared memory usage and its size limitations I have found solution from web 1 named tiling.
Invoke serial SAXPY kernel saxpy_serialn 20 x y. For int j 0. __global__ void copyfloat odata const float idata int x blockIdxx TILE_DIM threadIdxx.
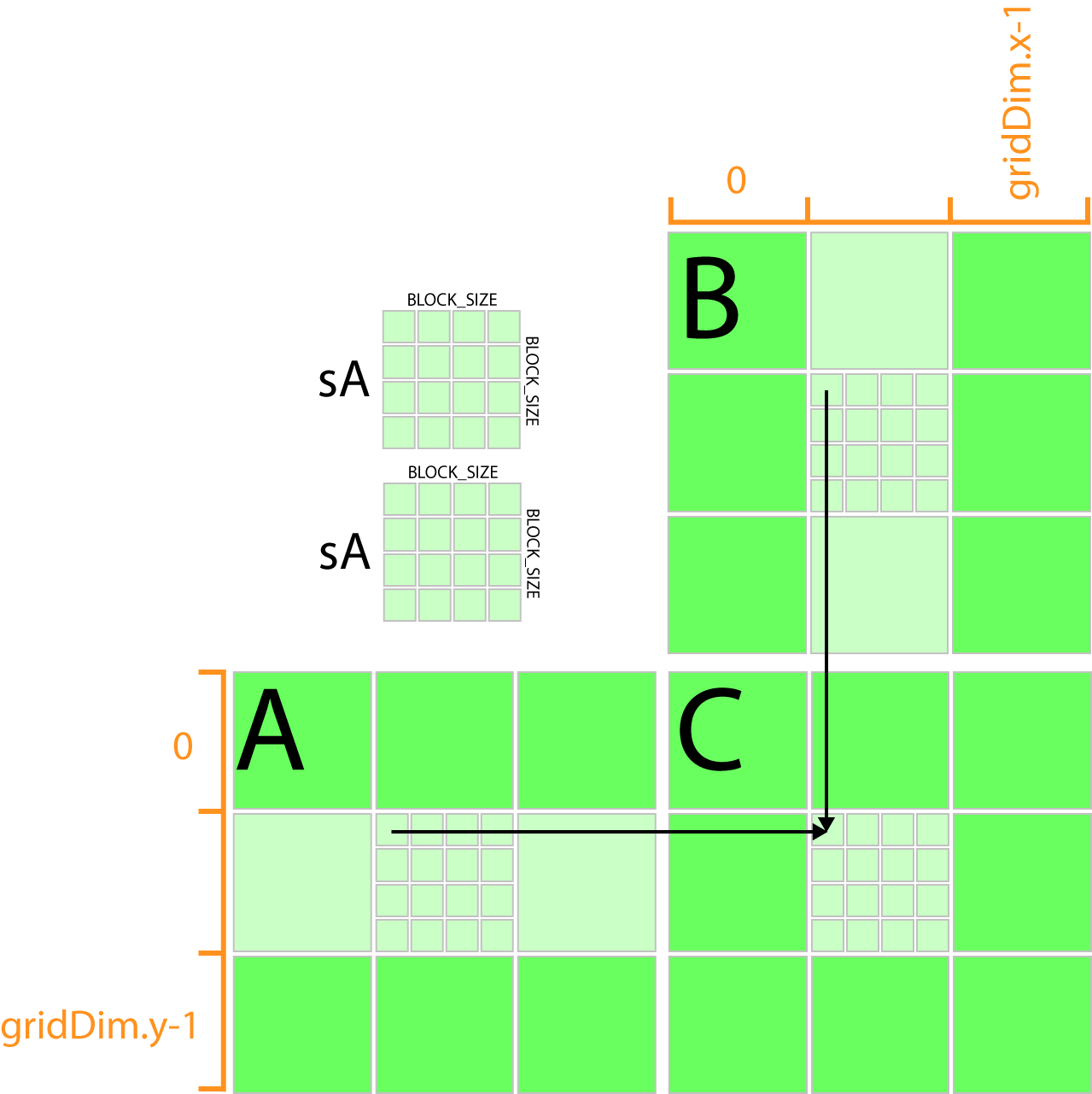
Each thread has an ID that it uses to compute memory addresses and make control decisions. TILED Matrix Multiplication in CUDA by using Shared Constant Memory. It ensures that extra threads do not do any work.
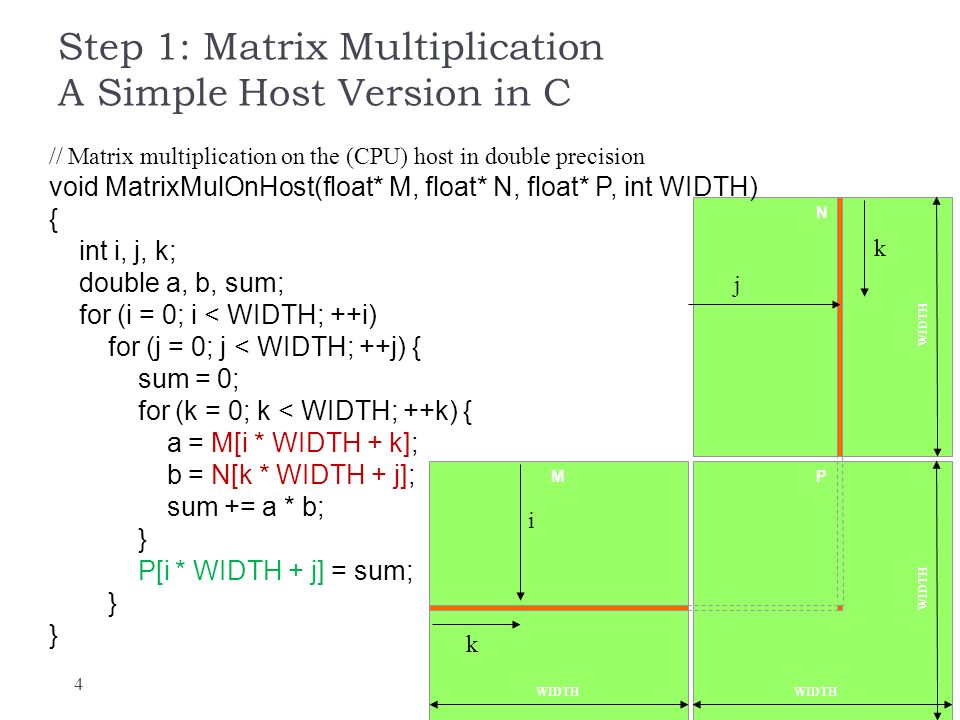
Implementing in CUDA We now turn to the subject of implementing matrix multiplication on a CUDA-enabled graphicscard. Int width gridDimx TILE_DIM. Viewed 4 times 0.
Y block_size_y threadIdx. For int k 0. Int y blockIdxy TILE_DIM threadIdxy.
Please type in m n and k. Test results following tests were carried out on a Tesla M2075 card lzhengchunclus10 liu aout. K Ci n j Ai n k Bk n j.
Time elapsed on matrix multiplication of 1024x1024. The above condition is written in the kernel. J BLOCK_ROWS odatayjwidth x.
X block_size_x threadIdx. 1 day agoHow to write a simple numba cuda kernel matrix multiplication plus array shifting Ask Question Asked today. Kernel is the function that can be executed in parallel in the GPU device.
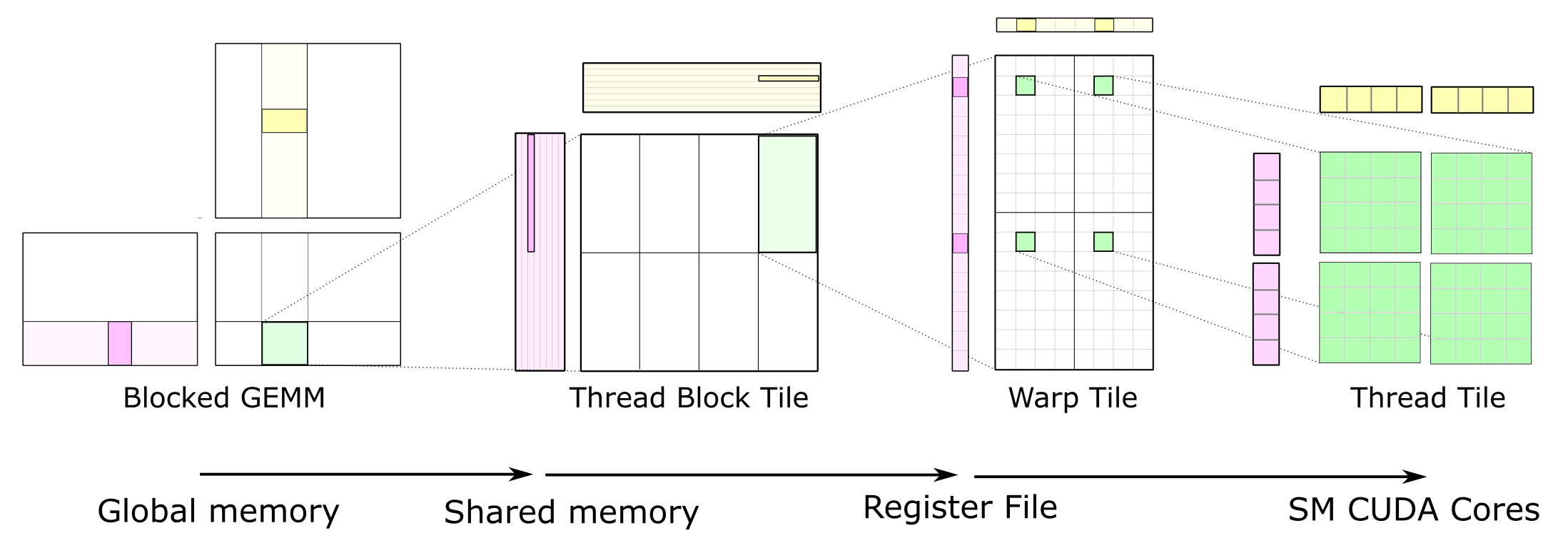
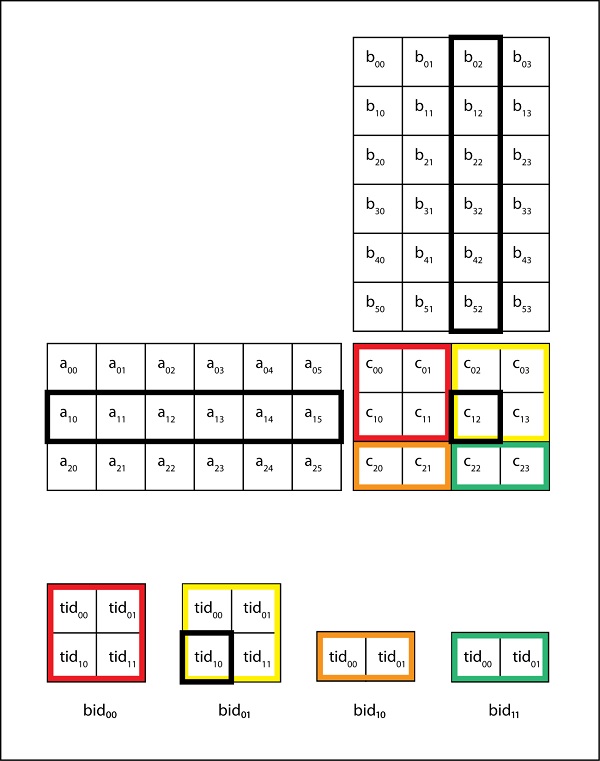
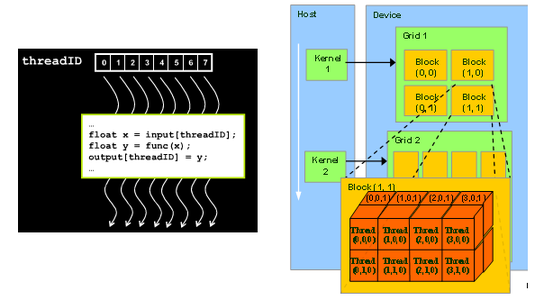
21 The CUDA Programming Model. A CUDA kernel is executed by an array of CUDA threads. The thread block tiles storing A and B have size 128-by-8 and 8-by-32 respectively.
All threads run the same code. The matmul kernel splits the output matrix into a grid of 128 x 128 submatrices each submatrix is assigned to a thread block. Void mm_kernel float A float B float Cint n for int k 0.
Writefile matmul_naivecu define WIDTH 4096 __global__ void matmul_kernel float C float A float B int x blockIdx. Although CUDA kernels may be compiled into sequential code that can be run on any architecture supported by a C compiler our SpMV kernels are designed to be run on throughput-oriented architectures in general and the NVIDIA GPU in. I have a simulation in which I iteratively update an array.
Matrix Multiplication on GPU using Shared Memory considering Coalescing and Bank Conflicts - kberkayCuda-Matrix-Multiplication. Matrix multiplication in CUDA this is a toy program for learning CUDA some functions are reusable for other purposes. We focus on the design of kernels for sparse matrix-vector multiplication.
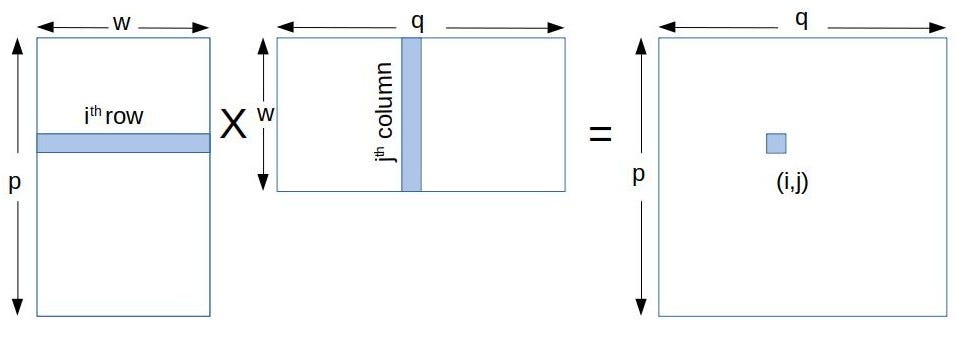
The formula used to calculate elements of d_P is. We will begin with a description of programming in CUDA then implement matrix mul-tiplication and then implement it in such a way that we take advantage of the faster sharedmemory on the GPU. Float sum 00.
Lets start by looking at the matrix copy kernel. This policy decomposes a matrix multiply operation into CUDA blocks each spanning a 128-by-32 tile of the output matrix. The fundamental part of the CUDA code is the kernel program.
CUDA kernel and threads. Matrix multiplication between a IxJ matrix d_M and JxK matrix d_N produces a matrix d_P with dimensions IxK. Some of the entries simply get shifted to new indices and the others are updated by a matrix multiplication followed by a sign function.

Partial Kernel Codes For Matrix Multiplication Cuda Keywords Are Bold Download Scientific Diagram

2 Matrix Matrix Multiplication Using Cuda Download Scientific Diagram
Matrix Multiplication In Cuda Ppt Download
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow

Multiplication Kernel An Overview Sciencedirect Topics

Tiled Matrix Multiplication Kernel It Shared Memory To Reduce Download Scientific Diagram
Matrix Multiplication In Cuda A Simple Guide By Charitha Saumya Analytics Vidhya Medium

Partial Kernel Codes For Matrix Multiplication Cuda Keywords Are Bold Download Scientific Diagram
Cuda Memory Model 3d Game Engine Programming
Cuda Reducing Global Memory Traffic Tutorialspoint
Https Edoras Sdsu Edu Mthomas Sp17 605 Lectures Cuda Mat Mat Mult Pdf
Running A Parallel Matrix Multiplication Program Using Cuda On Futuregrid

5kk73 Gpu Assignment Website 2014 2015
Cuda Optimization Design Tradeoff For Autonomous Driving By Paichun Jim Lin Medium

Multiplication Kernel An Overview Sciencedirect Topics
Massively Parallel Programming With Gpus Computational Statistics In Python 0 1 Documentation


Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow
Cs Tech Era Tiled Matrix Multiplication Using Shared Memory In Cuda