Cuda Matrix Vector Multiplication Kernel
I implemented a kernel for matrix-vector multiplication in CUDA C following the CUDA C Programming Guide using shared memory. Refer to vmppdf for a detailed paper describing the algorithms and testing suite.

Pseudo Code Of The Hmvm Kernel With Cuda Async Kernel One Thread Download Scientific Diagram
The GEMM CUDA kernel issues three concurrent streams of operations within the pipeline which correspond to the stages of.
Cuda matrix vector multiplication kernel. Matrix multiplication between a IxJ matrix d_M and JxK matrix d_N produces a matrix d_P with dimensions IxK. Yrow multiply_rowrow_end row_begin Ajrow_begin Avrow_begin x Parallel sparse matrixvector multiplication. It is assumed that the student is familiar with C programming but no other background is assumed.
We use the example of Matrix Multiplication to introduce the basics of GPU computing in the CUDA environment. Obvious way to implement our parallel matrix multiplication in CUDA is to let each thread do a vector-vector multiplication ie. Latest commit 46a5a8a on Apr 8 2013 HistoryHEN BlockMultiply.
The idea is that this kernel is executed with one thread per element in the output matrix. The CSR kernel contains two implementations. The goal of this project is to create a fast and efficient matrix-vector multiplication kernel for GPU computing in CUDA C.
GPUProgramming with CUDA JSC 24. Go to file T. One platform for doing so is NVIDIAs Compute Uni ed Device Architecture or CUDA.
Let me first present some benchmarking results which I did on a Jetson TK1 GPU. Rather than exclusively accumulate vector outer products. Although CUDA kernels may be compiled into sequential code that can be run on any architecture supported by a C compiler our SpMV kernels are designed to be run on throughput-oriented architectures in general and the NVIDIA GPU in particular.
If row int row_end Aprow1. Matrix-Vector Multiplication Using Shared and Coalesced Memory Access. The CSR vector kernel accesses indices and data contiguously therefore outperforms the CSR scalar kernel 4.
Here I guess cuBLAS does some magic since it seems that its execution is. Serial sparse matrixvector multiplication _global_void csrmul_kernelint Ap int Aj float Av int num_rows float x float y int row blockIdxxblockDimx threadIdxx. Ive implemented matrix-vector multiplication as a CUDA kernel and am using the trust lib for scan I was wondering if CUBLAS would be much faster as its probably better optimised than my code but I dont really want to commit much time to learning CUBLAS if I dont know in advance that its going to be that much better.
But one of my colleagues suggested me to inspect BLAS level 2 routines which implements various types of A x matrix vector operations. The above condition is written in the kernel. BlockMultiply Tranposed BlockMultiply Transpose T.
Go to line L. Each element in C matrix will be calculated by a. It ensures that extra threads do not do any work.
Naive CUDA kernel Well start with a very simple kernel for performing a matrix multiplication in CUDA. April 2017 Slide 2 Distribution of work Kernel function Each thread computes one element of the result matrix C n n threads will be needed Indexing of threads corresponds to 2d indexing. I was wondering if not only CUBLAS but any other implementation of BLAS has element-wise vectorvector multiplication implemented.
Matrix multiplication is a key computation within many scientific applications. As such each thread ij iterates over the entire row i in matrix A and column j in matrix B. And to be honest I wasnt able to find definitive answer yet.
The formula used to calculate elements of d_P is. We focus on the design of kernels for sparse matrix-vector multiplication. Tegra K1 compute capability 32 and a comparison with cuBLAS.
In CSR vector kernel each matrix row is processed by a whole warp 32 GPU threads while the CSR scalar kernel processes each row by one thread.
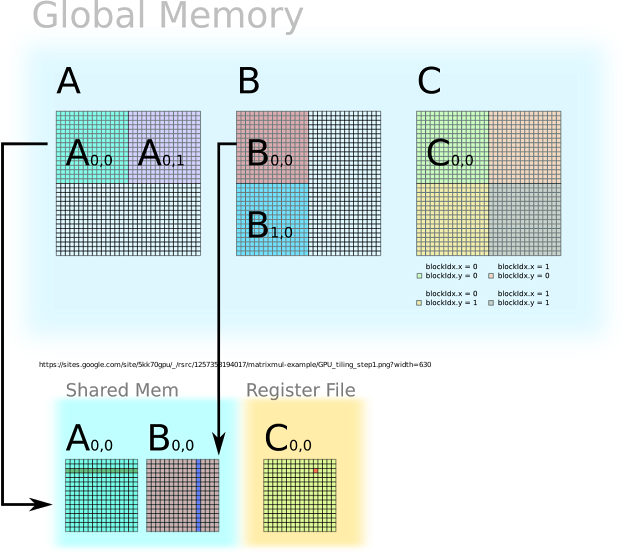
Cs Tech Era Tiled Matrix Multiplication Using Shared Memory In Cuda
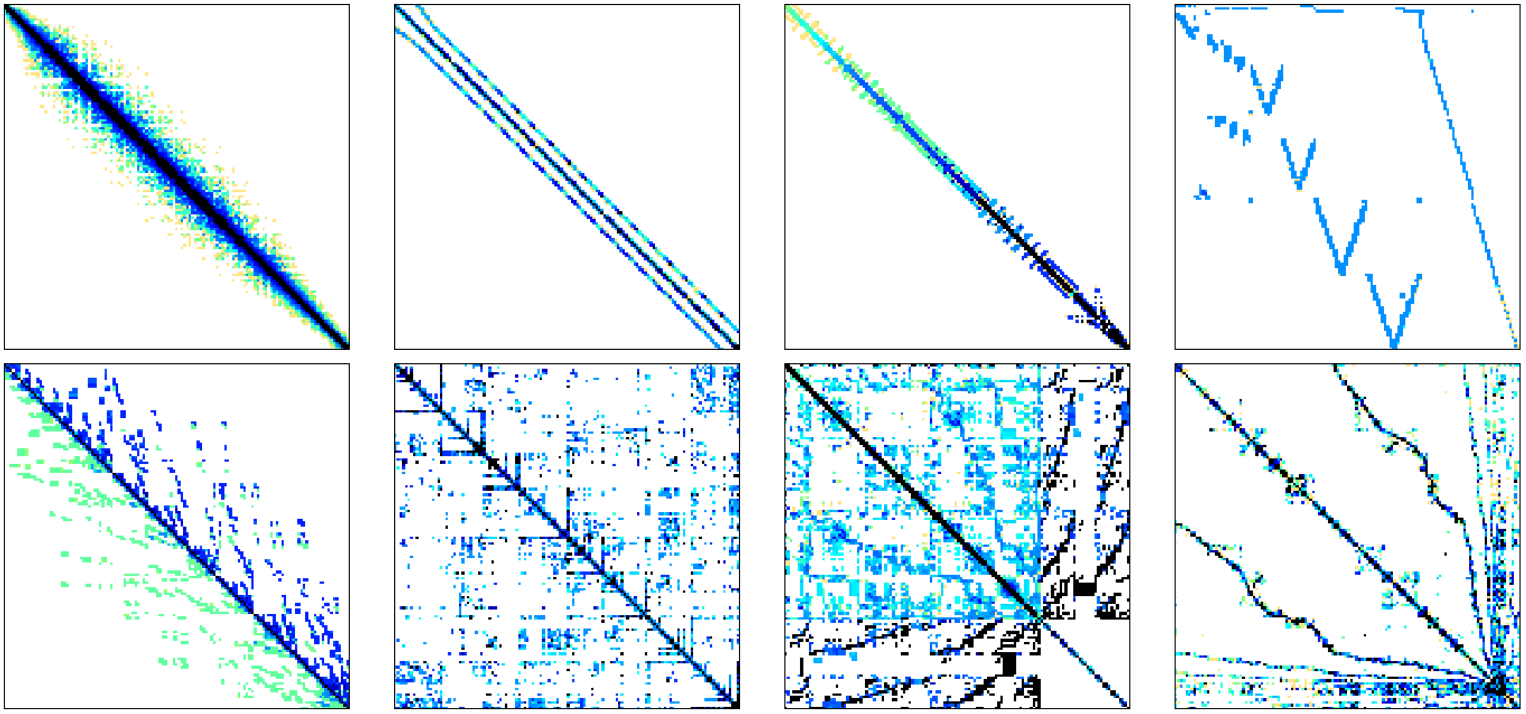
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium
Cuda Matrix Vector Multiplication Transpose Kernel Cu At Master Uysalere Cuda Matrix Vector Multiplication Github

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow

Simple Matrix Multiplication In Cuda Youtube

Multiplication Kernel An Overview Sciencedirect Topics

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow

Multiplication Kernel An Overview Sciencedirect Topics

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow

Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Multiplication Kernel An Overview Sciencedirect Topics
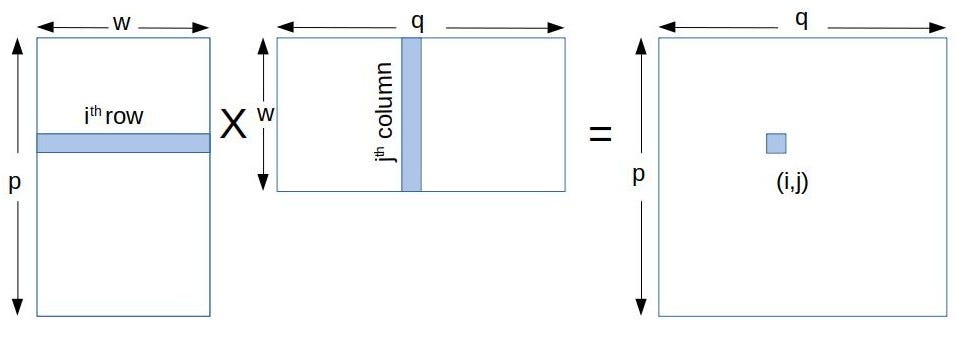
Matrix Multiplication In Cuda A Simple Guide By Charitha Saumya Analytics Vidhya Medium
Cuda Optimization Design Tradeoff For Autonomous Driving By Paichun Jim Lin Medium
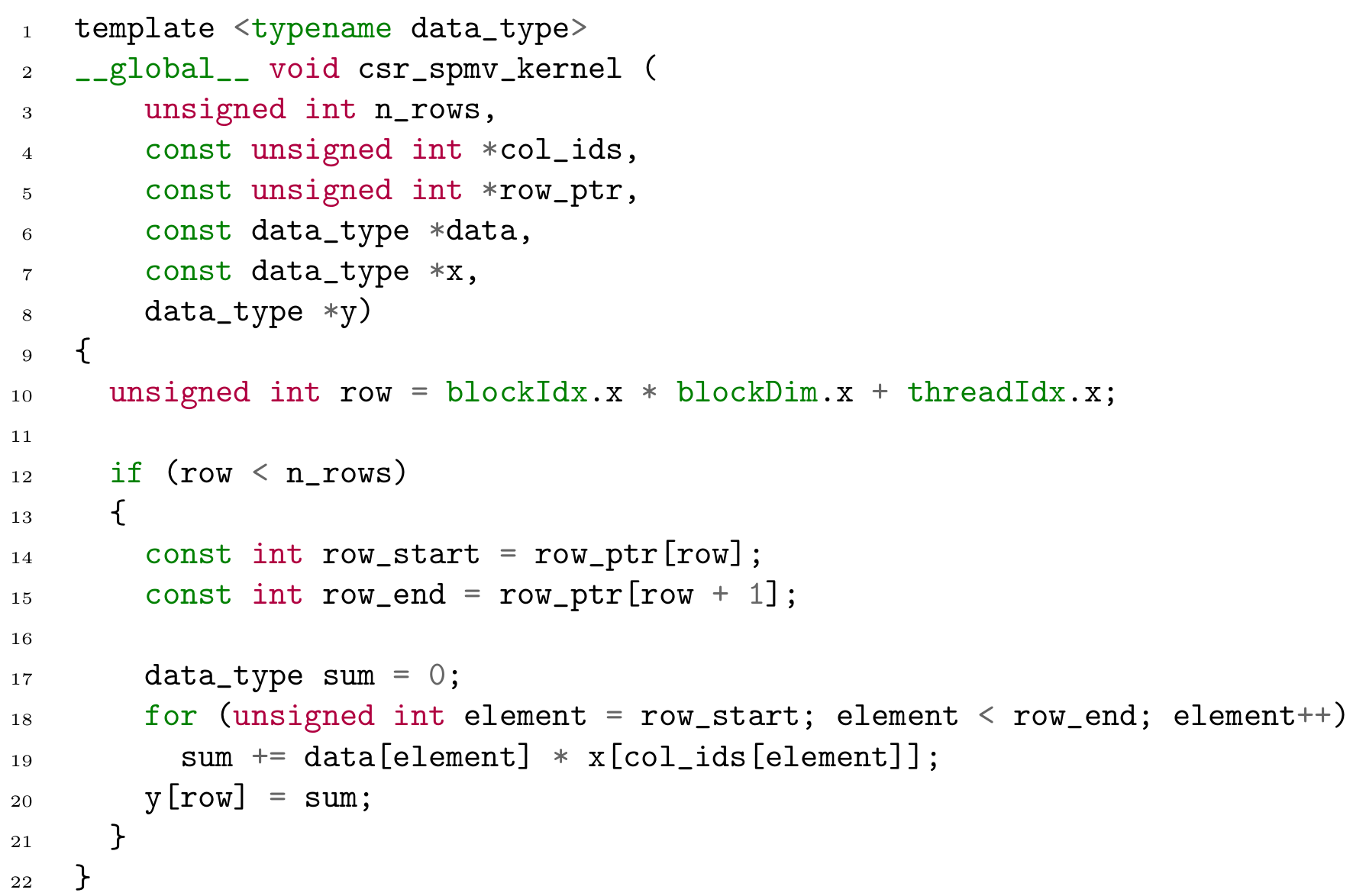
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium
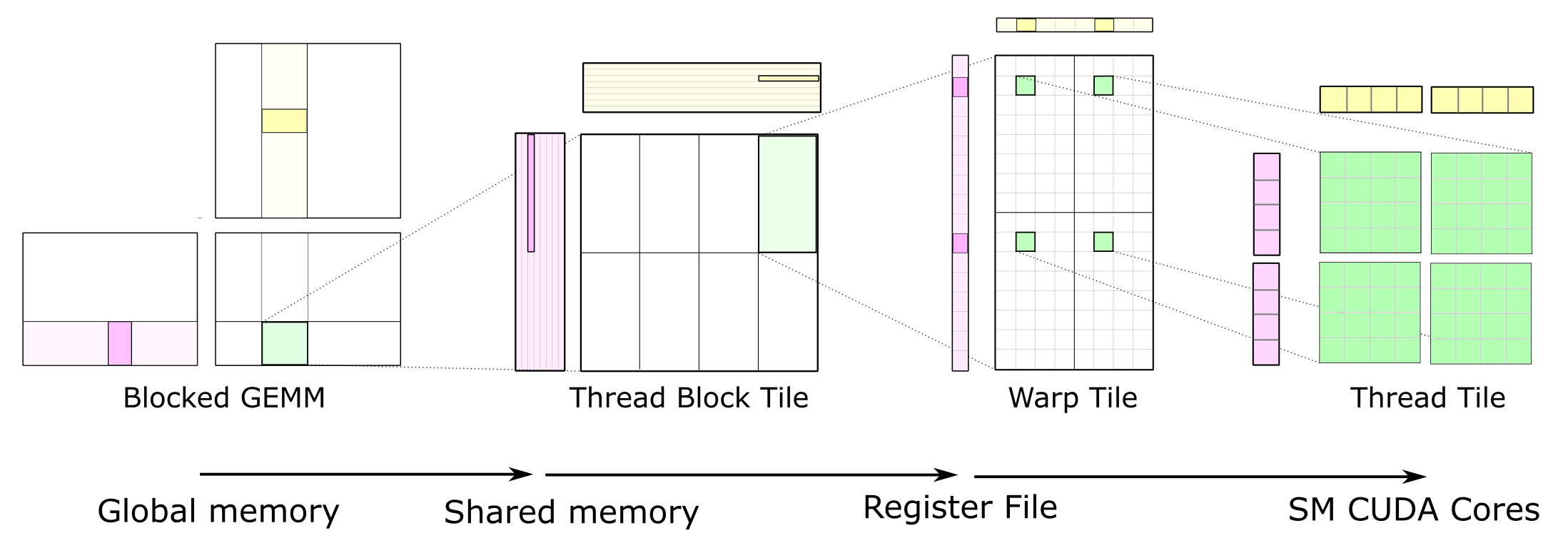
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog

The Tile Used In The Cuda Fortran Implementation Of The Matrix Vector Download Scientific Diagram
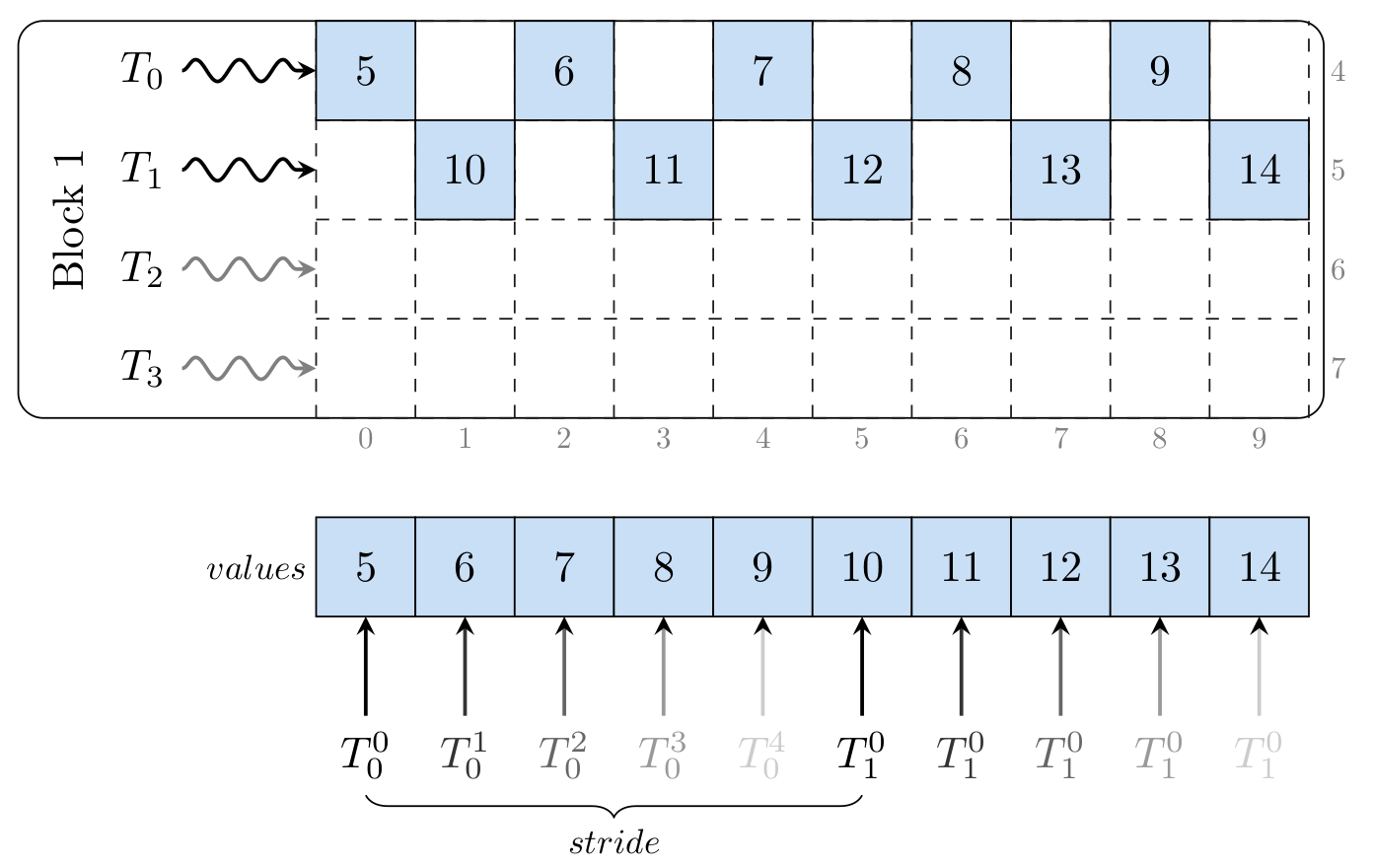
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Code Of Honour High Performance Matrix Vector Multiplication In Cuda C